I have started a YouTube channel and published one of the videos from my course. It’s the second video in the course and explains how and why we (theoretically) could have built (some of) Elasticsearch ourselves. It’s a great way of explaining the importance of the fundamental building blocks of a cluster: shards!
The video took a little over two years to go from conception to publishing, so there’s a bit of a story behind it. If you don’t want to hear it, you can find the video below. If you enjoy a bit of backstory, however, read on.
How the idea came about
I attended the Elasticsearch Engineer I & II courses in April 2019. I went into the training hoping to get some advanced knowledge about how a cluster operates and, initially, came away a bit disappointed. The courses still had a great deal of valuable material and there was a lot to like, but I didn’t feel… enlightened.
The next few weeks, however, gave my brain the space to fully realise the gravity of a simple diagram one of the instructors drew on the whiteboard. I’d scribbled it down in my notebook knowing I hadn’t quite grasped the full picture at the time.
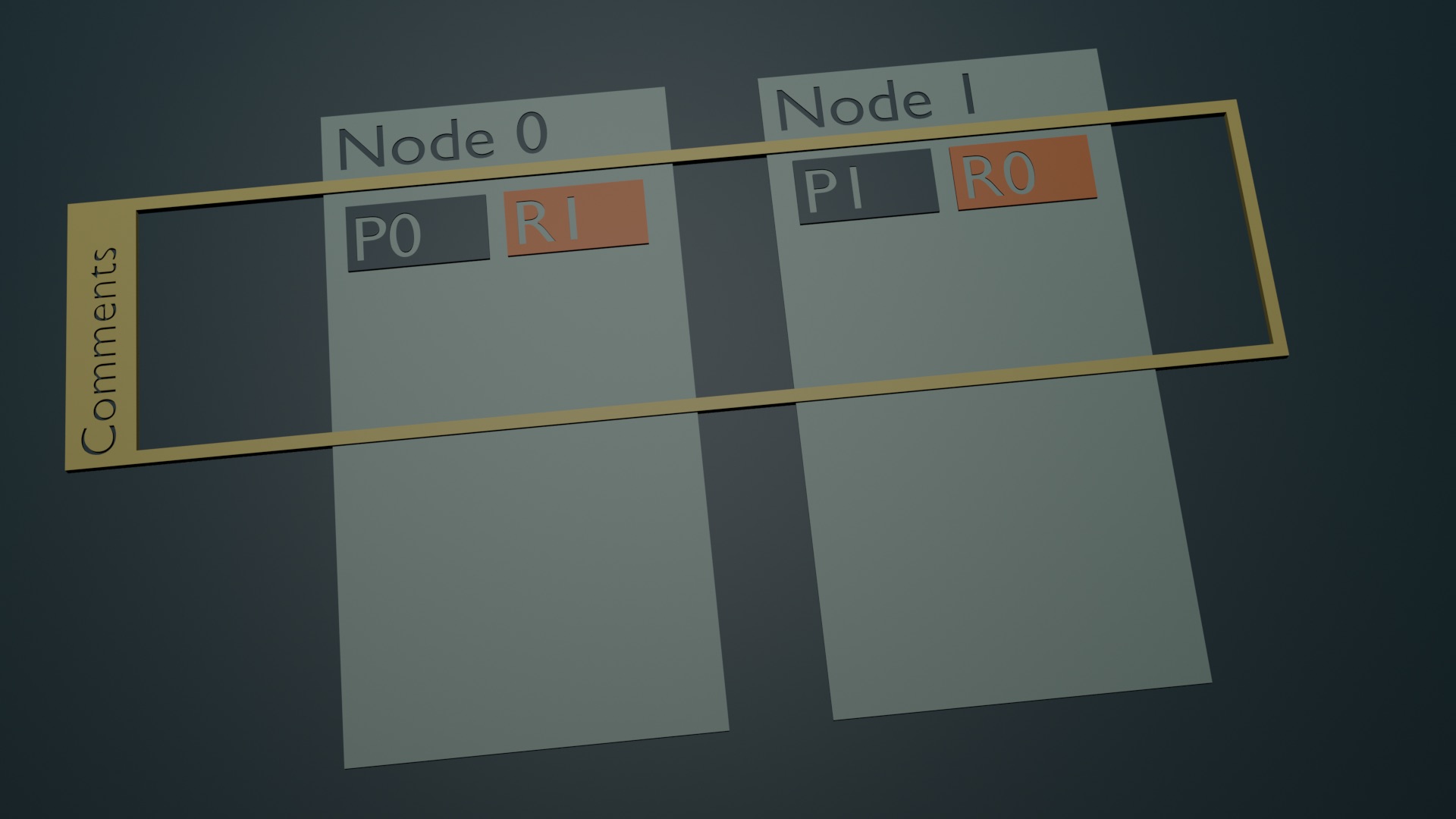
I came to appreciate that managing a cluster is really about just managing shards. How much data is in them? What sort of data is it? How is the data being queried? Does the JVM have enough memory? What’s going on with garbage collection? Everything is based on managing those Lucene instances.
Explaining what a shard is can be difficult and I’ve always found things easier to understand when you know the answer to one question: “Why does this thing even exist?”. If I could come up with a way to explain that data lives in shards, shards are distributed between nodes, and a node simply coordinates index and query operations between the shards that live on it, people could - hopefully - have the same new ‘Ah-ha!’ moment that I had.
I figured a good story would be building a distributed document store by starting with a single Lucene instance and building up from there, introducing each component when we need it. The initial git commit of the script was 11th November 2019.
A script isn’t a compelling video
I continued working on the script when inspiration struck, but I still had to figure out how the format of the video.
I knew from the start that I wanted to address some of what I don’t like about most tech tutorials. The main issue being that the presenter is almost never on camera. I’ve always felt like the video has more… integrity?… when you can see the presenter, and is often more engaging, too.
The visualisations in the video were always something I wanted to be a level or ten above what people are used to. I had such ambition for this but came nowhere close in the end. There was enough to figure out already with recording video and audio, editing, and not looking like a robot on camera. Building a complete 3D environment in Blender, figuring out materials and lighting, modelling, and keyframing animation, all for what normal people do in Powerpoint was going to take a significant time investment. The prototypes are still floating around and I may come back to them at some stage but not right now.
I also toyed with using a whiteboard or lightboard. I really like the idea of using a lightboard at some point in the future.
To get the ‘visualisations’ animated, another thing I tried was to raid the kids’ craft trolley, do some cutting and sticking, and record me moving marked-up pieces of paper around the table. This was simple and effective but not very… glamorous.
In April 2021 I threw in the towel and fired up Keynote. Twenty minutes later I had the slides. Some of them even had animations. It wasn’t what I had in mind originally but it worked. I hated to say it, but it was good enough.
Re-recording and publishing
I moved into a new office in May 2021 and decided that now was the time to actually get this video launched. I’d also decided to - once this first video was out - produce an entire video series on how to pass the Elastic Certified Engineer exam but with extra material that’s applicable to the real world. I’d be recording that in the office, so to not cause disruption to the zero viewers I currently had, I needed to re-record the one video I still hadn’t published.
Come July, I recorded it in a day, edited down the dozens of takes over the six hours of footage, knitted in the slides, ran the load tests with Rally for the extra video I’d told myself I needed to do, and exported and published the lot.
Accepting that I simply needed to get the video out so I can get on with building the main course was a massive turning point. Holding myself to the high standards I set was likely a form of procrastination. Letting that go was a big relief. Getting the videos done was an incredible amount of work, even after compromising on the visual marvel of the visualisations. I wrote this when I posted on LinkedIn about releasing the course:
In traditional Developer fashion, I massively underestimated the amount of work involved in doing this, now have a much clearer idea of what the problem really is, and - while still happy with the result - would like to completely re-do the whole thing at some stage!
Publishing felt wonderful. Seeing people enroll and complete the course felt even better.
There has still been work to do since then, like recording a quick intro to add to the YouTube version, posting on various sites such as Reddit, and adding captions to all the videos. I think I can draw a line under that course now, though. Until I rebuild the visualisations using Unity or Unreal Engine.
What’s next
The next series will be a full course to take you all the way from knowing a little about Elasticsearch to being able to pass the Elastic Certified Engineer exam and beyond, with a heavy focus on lab exercises. I’ve picked out some datasets to use, have built most of the curriculum, and am starting recording next week. I’m so pumped about starting recording that I’m going to the Turkish barber to get my beard into tip-top shape.
This course is a very different beast to the first one. The topics are concrete with a real implementation, unlike the first course which was almost completely abstract and conceptual. Lots of screen-sharing and a few slides means there will be much less of my face.
Something it has in common with the first course, however, is Lego.
I’m not going to wait until the course is finished to start taking orders; it will go on pre-sale once the first section is done. That first section covers installing Elasticsearch and building a lab environment to use through the course. Ansible and Docker will be in there too, but I’m leaving out Kubernetes because I’m not a complete glutton for punishment.
I’ll post on all the usual channels and notify people who have signed up for updates once the pre-sale goes live.
The YouTube channel will get occasional videos with tips and tricks, tutorials and disaster stories. It’ll be light-hearted and, with any luck, recording frequently will encourage me to not let my beard go completely wild.